2. NLP Pipelines¶
2.1. Traditional NLP Pipeline in NLTK¶
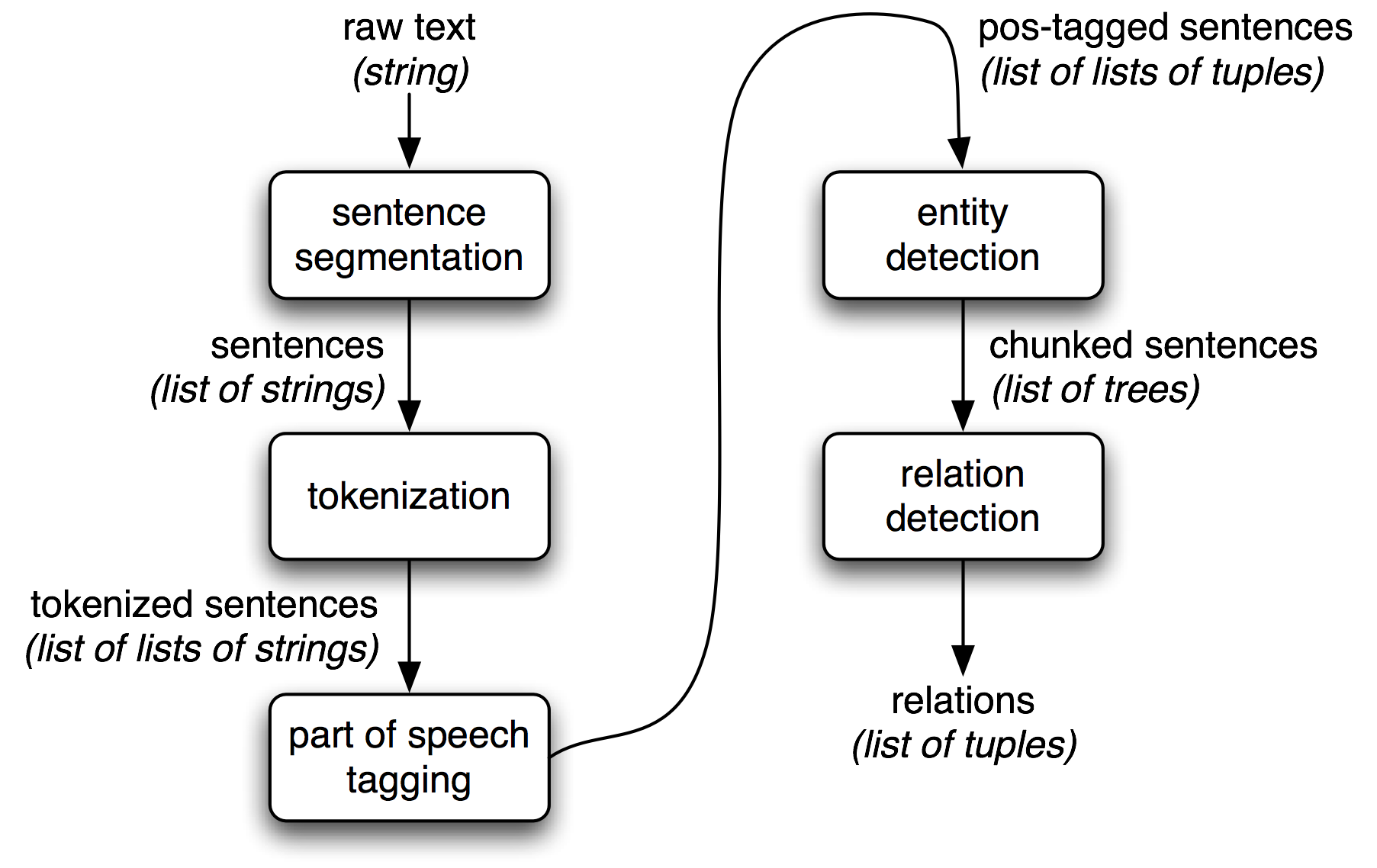
Image credit of Information Extraction in NLTK
import nltk
nltk.download('punkt') # Sentence Tokenize
nltk.download('averaged_perceptron_tagger') # POS Tagging
nltk.download('maxent_ne_chunker') # Named Entity Chunking
nltk.download('words') # Word Tokenize
# texts is a collection of documents.
# Here is a single document with two sentences.
texts = [u"A storm hit the beach in Perth. It started to rain."]
for text in texts:
sentences = nltk.sent_tokenize(text)
for sentence in sentences:
words = nltk.word_tokenize(sentence)
tagged_words = nltk.pos_tag(words)
ne_tagged_words = nltk.ne_chunk(tagged_words)
print(ne_tagged_words)
(S A/DT storm/NN hit/VBD the/DT beach/NN in/IN (GPE Perth/NNP) ./.)
(S It/PRP started/VBD to/TO rain/VB ./.)
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\wei\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] C:\Users\wei\AppData\Roaming\nltk_data...
[nltk_data] Package averaged_perceptron_tagger is already up-to-
[nltk_data] date!
[nltk_data] Downloading package maxent_ne_chunker to
[nltk_data] C:\Users\wei\AppData\Roaming\nltk_data...
[nltk_data] Package maxent_ne_chunker is already up-to-date!
[nltk_data] Downloading package words to
[nltk_data] C:\Users\wei\AppData\Roaming\nltk_data...
[nltk_data] Package words is already up-to-date!
2.2. Visualising NER in spaCy¶
We can use the Doc.user_data attribute to set a title for the visualisation.
from spacy import displacy
doc.user_data['title'] = "An example of an entity visualization"
displacy.render(doc, style='ent')
An example of an entity visualization
2.3. Write the visualisation to a file¶
We can inform the render to not display the visualisation in the Jupyter Notebook instead write into a file by calling the render with two extra argument:
jupyter=False, page=True
from pathlib import Path
# the page=True indicates that we want to write to a file
html = displacy.render(doc, style='ent', jupyter=False, page=True)
output_path = Path("C:\\Users\\wei\\CITS4012\\ent_visual.html")
output_path.open("w", encoding="utf-8").write(html)
758
2.4. NLP pipeline in spaCy¶
Recall that spaCy’s container objects represent linguistic units, suchas a text (i.e. document), a sentence and an individual token withlinguistic features already extracted for them.
How does spaCy create these containers and fill them withrelevant data?
A spaCy pipeline include, by default, a part-of-speech tagger (tagger), a dependency parser (parser), a lemmatizer (lemmatizer), an entity recognizer (ner), an attribute ruler (attribute_ruler and a word vectorisation model (tok2vec)).
import spacy
nlp = spacy.load('en_core_web_sm')
nlp.pipe_names
['tok2vec', 'tagger', 'parser', 'ner', 'attribute_ruler', 'lemmatizer']
spaCy allows you to load a selected set of pipeline components, dis-abling those that aren’t necessary.
You can do this either when creating a nlp object or disable it after the nlp object is created.
nlp = spacy.load('en_core_web_sm',disable=['parser'])
nlp.disable_pipes('tagger')
nlp.disable_pipes('parser')
2.5. Customising a NLP pipe in spaCy¶
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(u'I need a taxi to Cottesloe.')
for ent in doc.ents:
print(ent.text, ent.label_)
Cottesloe GPE
What if?
If we would like to introduce a new entity type SUBURB for Cottesloe and other suburb names, how should we informthe NER component about it?
Steps of Customising a spaCy NER pipe
Create a training example to show the entity recognizer so it will learn what to apply the SUBURB label to;
Add a new label called SUBURB to the list of supported entitytypes;
Disable other pipe to ensure that only the entity recogniser will beupdated during training;
Start training;
Test your new NER pipe;
Serialise the pipe to disk;
Load the customised NER
import spacy
nlp = spacy.load('en_core_web_sm')
# Specify new label and training data
LABEL = 'SUBURB'
TRAIN_DATA = [('I need a taxi to Cottesloe',
{ 'entities': [(17, 26, 'SUBURB')] }),
('I like red oranges', { 'entities': []})]
# Add new label to the ner pipe
ner = nlp.get_pipe('ner')
ner.add_label(LABEL)
1
# Train
optimizer = nlp.create_optimizer()
import random
from spacy.tokens import Doc
from spacy.training import Example
for i in range(25):
random.shuffle(TRAIN_DATA)
for text, annotations in TRAIN_DATA:
doc = Doc(nlp.vocab, words=text.split(" "))
# We need to create a training example object
example = Example.from_dict(doc, annotations)
nlp.update([example], sgd=optimizer)
# Test
doc = nlp(u'I need a taxi to Crawley')
for ent in doc.ents:
print(ent.text, ent.label_)
Crawley SUBURB
# Serialize the entire model to disk
nlp.to_disk('C:\\Users\\wei\\CITS4012') # Windows Path
# Load spacy model from disk
import spacy
nlp_updated = spacy.load('C:\\Users\\wei\\CITS4012')
# Test
doc = nlp_updated(u'I need a taxi to Subiaco')
for ent in doc.ents:
print(ent.text, ent.label_)
Subiaco SUBURB
Your Turn
Replace the suburb name with a few others, for example ‘Claremont’, ‘Western Australia’ and see what the the entity label is.
Take a look at the directory and see how the
nlpmodel is stored.This blog post on How to Train spaCy to Autodetect New Entities (NER) [Complete Guide] has more extensive examples on how to train a ner model with more data.