Lab09: CNN for NLP¶
In this lab, we will first use a small dataset (Frankenstein) to illustrate how to train CBOW from scratch.
We then introduce the basic building blocks of Convolutional Neural Networks (CNNs), and finally demontrate the use of CNN as a featurizer for news title classification, using pretrained GloVe embeddings as the input layer to CNN.
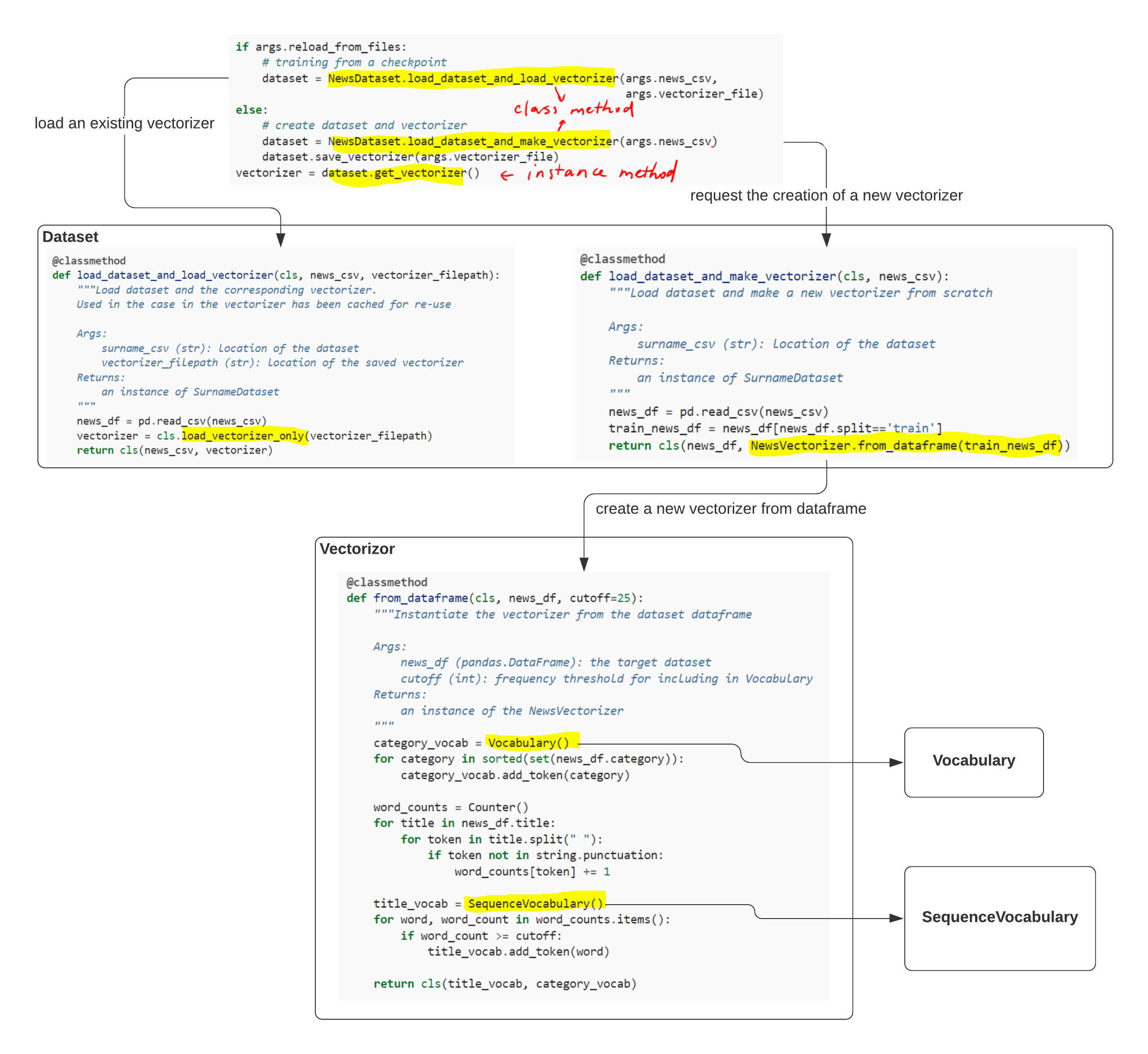
The pipeline from text to vectorized minibatch is mostly standard. Therefore in the past couple of labs we decompose the task of turning text into vectorized minibatch by writing resuable classes (Dataset, DataLoader, Vocabulary and Vectorizer). However, the object-oriented code is not as easy to read as pure procedule based programming style. Below is an illustration of the pipeline using the news title classification to demonstrate how the program control flows. To understand the code in Section 5 better, for example,we should start from the Initialization Step (Section 5.4.3). As you can see, this pipeline for text dataset preparation is a general pattern used in most neural language model training.
Credit: the notebooks are adapted from Chapter 5 of Natural Language Processing with PyTorch