2. Introduction to Pytorch Tensors¶
Pytorch is an optimised tensor manipulation library that offers an array of packages for deep learning. As compared to static frameworks such as Theano, Caffe and Tensorflow, Pytorch is in the family of dynamic frameworks, which does not require pre-defined computational graphs. This allows for a more flexible, imperative style of development, as it does not require the computational graphs to be first declared, compiled, and then excuted. However, this is potentially at the cost of computational efficiency, which makes it not as advantageous for production and mobile settings, but extremely useful during research and development.

Reference: Natural Lanuage Processing with PyTorch - Building intelligent lanaguage applications using deep learning, by Delip Rao and Brian McMahan (copyright O’REILLY Feb 2019)
2.1. Tensors¶
Tensor
A tensor is a mathematical object holding some multidimensional data.
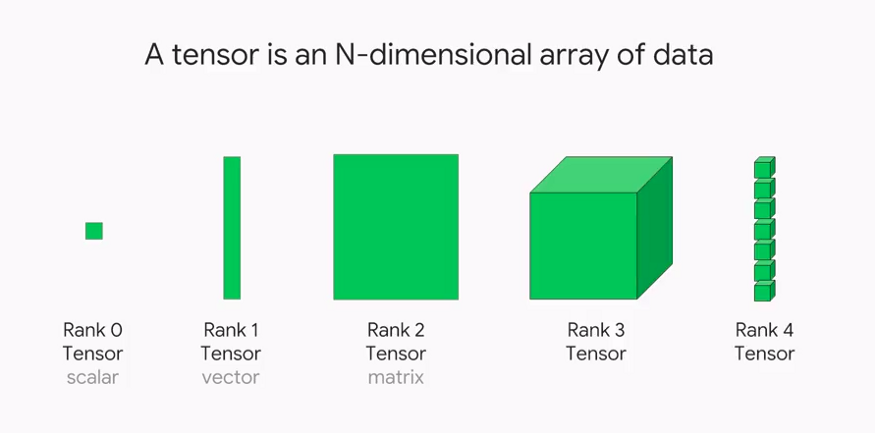
A tensor of order zero is just a number, or a
scalar.A tensor of order one (1st-order tensor) is an array of numbers, or a
vector.A tensor of order two (2nd-order tensor) is an array of vectors, or a
matrix.A tenosr of order n (nth-order tensor) is a generalised n-dimensional array of scalars.
2.2. Creating Tensors¶
You can create tensors in PyTorch pretty much the same way you create arrays in
Numpy. Using tensor() you can create either a scalar or a tensor.
PyTorch’s tensors have equivalent functions as its Numpy counterparts, like:
ones(), zeros(), rand(), randn() and many more. In the example below, we create one of each: scalar, vector, matrix and tensor or, saying it differently, one scalar and three tensors.
import torch
scalar = torch.tensor(3.14159)
vector = torch.tensor([1, 2, 3])
matrix = torch.ones((2, 3), dtype=torch.float)
# two (2) 3x4 matrices
tensor = torch.randn((2, 3, 4), dtype=torch.float)
print(scalar)
print(vector)
print(matrix)
print(tensor)
tensor(3.1416)
tensor([1, 2, 3])
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[[-0.1062, 0.0259, 1.0003, 1.7506],
[ 1.5519, 0.5936, 0.0977, 1.0550],
[-0.8436, -0.2855, 0.0348, -1.2236]],
[[-0.7193, -1.7311, 0.3547, -2.5190],
[ 0.6258, -0.6508, -0.4601, -0.4112],
[ 0.6510, 0.2963, -0.1989, 0.3999]]])
2.2.1. A helper function describe(x)¶
Given a torch tensor x, we can use either x.size() function or x.shape property to look at the dimensionality of the torch tensor.
Note
tensor.shape is a property, not a callable function, whereas tensor.size() is a function.
def describe(x):
print("Type:{}".format(x.type()))
print("Shape:{}".format(x.shape))
print("Size():{}".format(x.size()))
print("Values: \n{}".format(x))
describe(scalar)
Type:torch.FloatTensor
Shape:torch.Size([])
Size():torch.Size([])
Values:
3.141590118408203
describe(vector)
Type:torch.LongTensor
Shape:torch.Size([3])
Size():torch.Size([3])
Values:
tensor([1, 2, 3])
describe(matrix)
Type:torch.FloatTensor
Shape:torch.Size([2, 3])
Size():torch.Size([2, 3])
Values:
tensor([[1., 1., 1.],
[1., 1., 1.]])
describe(tensor)
Type:torch.FloatTensor
Shape:torch.Size([2, 3, 4])
Size():torch.Size([2, 3, 4])
Values:
tensor([[[-0.1062, 0.0259, 1.0003, 1.7506],
[ 1.5519, 0.5936, 0.0977, 1.0550],
[-0.8436, -0.2855, 0.0348, -1.2236]],
[[-0.7193, -1.7311, 0.3547, -2.5190],
[ 0.6258, -0.6508, -0.4601, -0.4112],
[ 0.6510, 0.2963, -0.1989, 0.3999]]])
2.2.2. Creating a tensor with torch.Tensor()¶
describe(torch.Tensor(2,3))
Type:torch.FloatTensor
Shape:torch.Size([2, 3])
Size():torch.Size([2, 3])
Values:
tensor([[0.0000e+00, 0.0000e+00, 2.1019e-44],
[0.0000e+00, 1.4013e-45, 0.0000e+00]])
Warning
You might have noted that we can create tensors using both torch.tensor() and torch.Tensor(), note the subtle difference between the case of letter “t”.
torch.Tensor is an alias for torch.FloatTensor, which creates tensors of float type.
torch.tensor on the other hand, infers the dtype automatically, and allows explicit specification of dtype during creation.
So let’s stick to torch.tensor instead.
2.2.3. Creating a randomly initialized tensor¶
import torch
describe(torch.rand(2,3)) # uniform random
describe(torch.randn(2,3)) # normal random
Type:torch.FloatTensor
Shape:torch.Size([2, 3])
Size():torch.Size([2, 3])
Values:
tensor([[0.2609, 0.1867, 0.2250],
[0.7788, 0.2673, 0.5694]])
Type:torch.FloatTensor
Shape:torch.Size([2, 3])
Size():torch.Size([2, 3])
Values:
tensor([[ 0.5022, -1.1496, -0.6783],
[ 0.7880, -0.0197, 1.7654]])
2.2.4. Creating a filled tensor¶
import torch
describe(torch.zeros(2,3))
x = torch.ones(2,3)
describe(x)
x.fill_(5)
describe(x)
Type:torch.FloatTensor
Shape:torch.Size([2, 3])
Size():torch.Size([2, 3])
Values:
tensor([[0., 0., 0.],
[0., 0., 0.]])
Type:torch.FloatTensor
Shape:torch.Size([2, 3])
Size():torch.Size([2, 3])
Values:
tensor([[1., 1., 1.],
[1., 1., 1.]])
Type:torch.FloatTensor
Shape:torch.Size([2, 3])
Size():torch.Size([2, 3])
Values:
tensor([[5., 5., 5.],
[5., 5., 5.]])
2.2.5. Creating and initialising a tensor from lists¶
Observe the type difference between the torch.tensor() and torch.Tensor().
x = torch.tensor([[1, 2, 3],
[4, 5, 6]])
describe(x)
Type:torch.LongTensor
Shape:torch.Size([2, 3])
Size():torch.Size([2, 3])
Values:
tensor([[1, 2, 3],
[4, 5, 6]])
x = torch.tensor([[1, 2, 3],
[4, 5, 6]])
describe(x)
Type:torch.LongTensor
Shape:torch.Size([2, 3])
Size():torch.Size([2, 3])
Values:
tensor([[1, 2, 3],
[4, 5, 6]])
2.2.6. Creating and initialising a tensor from Numpy¶
from_numpy() automatically inherits input array dtype. On the other hand, torch.Tensor is an alias for torch.FloatTensor.
Therefore, if you pass int32 array to torch.Tensor, output tensor is float tensor and they wouldn’t share the storage. torch.from_numpy gives you torch.LongTensor as expected.
import torch
import numpy as np
a = np.arange(10)
describe(torch.from_numpy(a))
Type:torch.IntTensor
Shape:torch.Size([10])
Size():torch.Size([10])
Values:
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=torch.int32)
describe(torch.Tensor(a))
Type:torch.FloatTensor
Shape:torch.Size([10])
Size():torch.Size([10])
Values:
tensor([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
describe(torch.tensor(a))
Type:torch.IntTensor
Shape:torch.Size([10])
Size():torch.Size([10])
Values:
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=torch.int32)
2.2.7. Subtleties in Torch Memory Model¶
Another way of creating tensor is to use torch.as_tensor(). What’s the difference between torch.as_tensor() and torch.tensor()?
torch.tensor always copies the data. For example, torch.tensor(x) is equivalent to x.clone().detach().
torch.as_tensor always tries to avoid copies of the data. One of the cases where as_tensor avoids copying the data is if the original data is a numpy array.
It is not always necessary or a good idea to copy and create a new tensor, especially when the tensor is large.
2.2.8. Reshaping a tensor¶
The same subtle difference exists between the methods that change the shape of a tensor, i.e. view() and reshape().
Important
The view() method only returns a tensor with the
desired shape that shares the underlying data with the original
tensor - it DOES NOT create a new, independent, tensor!
The reshape() method may or may not create a copy! The
reasons behind this apparently weird behavior are beyond the
scope of this section - but this behavior is the reason why view()
is preferred :-)
Why does it matter? Using view(), we get the same tensor with a different shape, any modification to the reshaped tensor will change the original tensor.
# We get a tensor with a different shape but it still is
# the SAME tensor
same_matrix = matrix.view(1, 6)
# If we change one of its elements...
same_matrix[0, 1] = 2.
# It changes both variables: matrix and same_matrix
print(matrix)
print(same_matrix)
tensor([[1., 2., 1.],
[1., 1., 1.]])
tensor([[1., 2., 1., 1., 1., 1.]])
To copy all data into a separate independent tensor in the memory, so future operations will not affect the orignal, we will need to use new_tensor() or clone() methods.
# We can use "new_tensor" method to REALLY copy it into a new one
different_matrix = matrix.new_tensor(matrix.view(1, 6))
# Now, if we change one of its elements...
different_matrix[0, 1] = 3.
# The original tensor (matrix) is left untouched!
# But we get a "warning" from PyTorch telling us
# to use "clone()" instead!
print(matrix)
print(different_matrix)
tensor([[1., 2., 1.],
[1., 1., 1.]])
tensor([[1., 3., 1., 1., 1., 1.]])
C:\Users\wei\AppData\Local\Temp/ipykernel_10816/887542709.py:2: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than tensor.new_tensor(sourceTensor).
different_matrix = matrix.new_tensor(matrix.view(1, 6))
Warning
As from the warning message, we in fact should use matrix.clone().detach() to copy a tensor into a new duplicate, rather than matrix.new_tensor().
In summary, the preferred functions are:
from a list of values, use
torch.tensor(values, dtype="")from numpy, use
torch.from_numpy()ortorch.as_tensor()to avoid data copying.from numpy, use
torch.tensor()to copy it into a new tensor.from an existing tensor,
sourceTensor.view()to avoid copying.from an existing tensor,
sourceTensor.clone().detach()for a fresh duplicate.
2.3. Tensor Slicing, Indexing and Joining¶
import torch
from functions import describe
x = torch.arange(6).view(2,3)
describe(x)
Type:torch.LongTensor
Shape/size:torch.Size([2, 3])
Values:
tensor([[0, 1, 2],
[3, 4, 5]])
2.3.1. Contiguous Indexing using [:a, :b]¶
The code below accesses up to row 1 but not including row 1, and up to col 2, but no including col 2.
describe(x[:1, :2])
Type:torch.LongTensor
Shape/size:torch.Size([1, 2])
Values:
tensor([[0, 1]])
2.3.2. Noncontiguous Indexing¶
Using function torch.index_select(), the code below accesses column (dim=1) indexed by 0 and 2.
indices = torch.LongTensor([0, 2])
describe(torch.index_select(x, dim=1, index=indices))
Type:torch.LongTensor
Shape/size:torch.Size([2, 2])
Values:
tensor([[0, 2],
[3, 5]])
You can duplicate the same row or column multiple times, by specifying the same index multiple times.
indices = torch.LongTensor([0, 0, 0])
describe(torch.index_select(x, dim=0, index=indices))
Type:torch.LongTensor
Shape/size:torch.Size([3, 3])
Values:
tensor([[0, 1, 2],
[0, 1, 2],
[0, 1, 2]])
Use indices directly [inices_list, indices_list] can also achieve the same outcome.
row_indices = torch.arange(2).long()
col_indices = torch.LongTensor([0,2])
describe(x[row_indices, col_indices])
Type:torch.LongTensor
Shape/size:torch.Size([2])
Values:
tensor([0, 5])
describe(x[[0,1], [0,2]])
Type:torch.LongTensor
Shape/size:torch.Size([2])
Values:
tensor([0, 5])
2.3.3. Concatenating Tensors¶
x = torch.arange(6).view(2,3)
describe(x)
Type:torch.LongTensor
Shape/size:torch.Size([2, 3])
Values:
tensor([[0, 1, 2],
[3, 4, 5]])
describe(torch.cat([x, x], dim=0))
Type:torch.LongTensor
Shape/size:torch.Size([4, 3])
Values:
tensor([[0, 1, 2],
[3, 4, 5],
[0, 1, 2],
[3, 4, 5]])
describe(torch.cat([x, x], dim=1))
Type:torch.LongTensor
Shape/size:torch.Size([2, 6])
Values:
tensor([[0, 1, 2, 0, 1, 2],
[3, 4, 5, 3, 4, 5]])
describe(torch.stack([x, x], dim=1))
Type:torch.LongTensor
Shape/size:torch.Size([2, 2, 3])
Values:
tensor([[[0, 1, 2],
[0, 1, 2]],
[[3, 4, 5],
[3, 4, 5]]])
2.3.4. Linear Algebra on tensors: multiplication¶
x1 = torch.arange(6).view(2,3).float()
describe(x1)
Type:torch.FloatTensor
Shape/size:torch.Size([2, 3])
Values:
tensor([[0., 1., 2.],
[3., 4., 5.]])
Warning
torch.arange() creates LongTensor, for torch.mm(), we need to convert the LongTensor to FloatTensor by using x.float().
x2 = torch.ones(3,2)
x2[:, 1] += 1
describe(x2)
Type:torch.FloatTensor
Shape/size:torch.Size([3, 2])
Values:
tensor([[1., 2.],
[1., 2.],
[1., 2.]])
describe(torch.mm(x1, x2))
Type:torch.FloatTensor
Shape/size:torch.Size([2, 2])
Values:
tensor([[ 3., 6.],
[12., 24.]])
2.4. CUDA tensors¶
So far, we have only created CPU tensors. What does it mean? It means the data in the tensor is stored in the computer’s main memory and any operations performed on it are going to be handled by its CPU (the Central Processing Unit, for instance, an Intel® Core™ i7 Processor). So, although the data is, technically speaking, in the memory, we’re still calling this kind of tensor a CPU tensor.
A GPU (which stands for Graphics Processing Unit) is the processor of a graphics card. These tensors store their data in the graphics card’s memory and operations on top of them are performed by the GPU.
If you have a graphics card from NVIDIA, you can use the power of its GPU to speed up model training. PyTorch supports the use of these GPUs for model training using CUDA (Compute Unified Device Architecture), which needs to be previously installed and configured (please refer to the Setup Guide for more information on this).
If you do have a GPU (and you managed to install CUDA), we’re getting to the part where you get to use it with PyTorch. But, even if you do not have a GPU, you should stick around in this section anyway… why? First, you can use a free GPU from Google Colab and, second, you should always make your code GPU-ready, that is, it should automatically run in a GPU, if one is available.
print(torch.cuda.is_available())
True
# prefered method: device agnostic tensor instantiation
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
cuda
So, if you don’t have a GPU, your device is called cpu. If you do have a GPU, your device is called cuda or cuda:0.
If you have multiple GPUs, and want to check how many GPUs it
has, or which model they are, you can figure it out using cuda.device_count() and
cuda.get_device_name():
n_cudas = torch.cuda.device_count()
for i in range(n_cudas):
print(torch.cuda.get_device_name(i))
NVIDIA GeForce RTX 3080
We can use .to(device) to turn our tensor to a GPU tensor if you have a GPU device.
x = torch.rand(3,2).to(device)
describe(x)
Type:torch.cuda.FloatTensor
Shape/size:torch.Size([3, 2])
Values:
tensor([[0.3817, 0.3665],
[0.9877, 0.7927],
[0.9034, 0.5782]], device='cuda:0')
Warning
Mixing CUDA tensors with CPU-bound tensors will lead to errors. This is because we need to ensure the tensors are on the same device.
y = torch.rand(3,2)
x + y
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_10816/1126695582.py in <module>
1 y = torch.rand(3,2)
----> 2 x + y
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
cpu_device = torch.device("cpu")
x = x.to(cpu_device)
y = y.to(cpu_device)
x + y
tensor([[0.6276, 0.9583],
[0.7592, 1.2605],
[1.0946, 0.9480]])
Note
It is expensive to move data back and forth from the GPU. Best practice is to carry out as much computation on GPU as possible and then just transfering the final results to CPU.