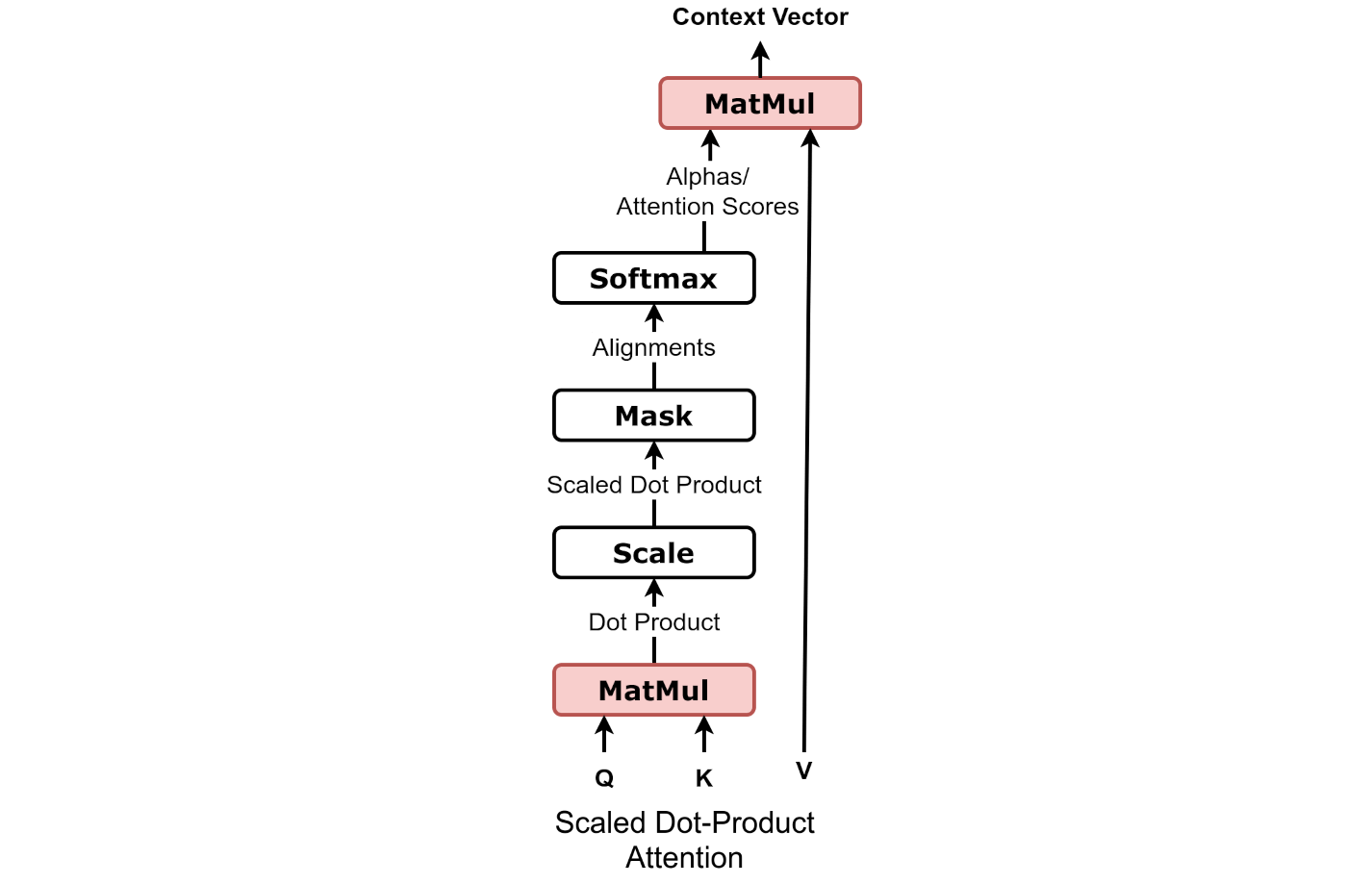
1. Attention Mechanism¶
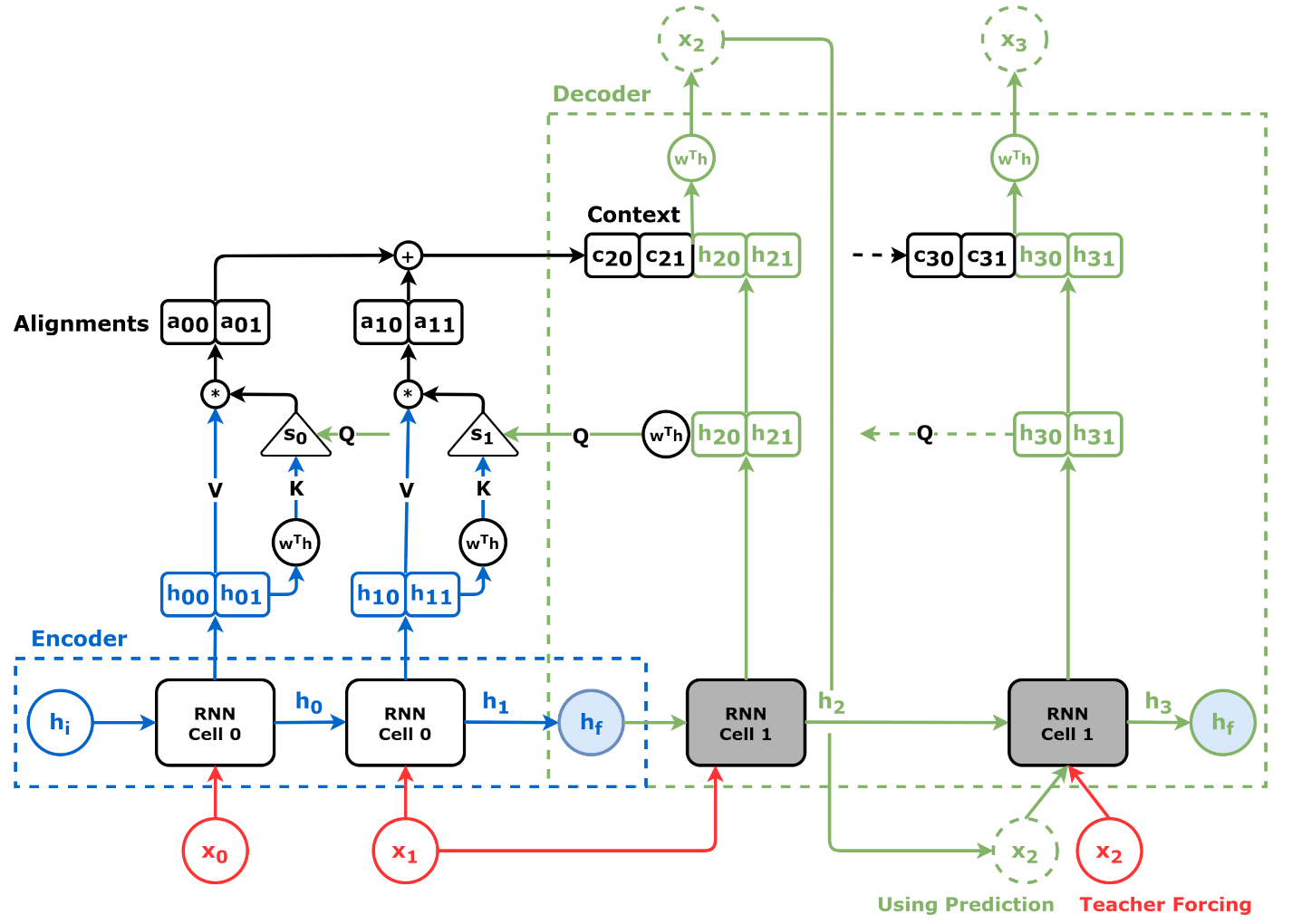
In this notebook, we introduce the attention mechanism to our plain sequence to sequence model, as illustrated in the diagram below:
1.1. Download Untility Files for Plotting and Data Generation¶
Download these utility functions first and place them in the same directory as this notebook. These files are the same as the ones in Lab11 Sequence to Sequence Model.
from IPython.display import FileLink, FileLinks
FileLink('plots.py')
FileLink('plots_seq2seq.py')
FileLink('util.py')
FileLink('replay.py')
1.2. Imports¶
import copy
import numpy as np
import torch
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, Dataset, random_split, TensorDataset
from util import StepByStep
from plots import *
from plots_seq2seq import *
1.3. Data Generation¶
We still make use of the Square Sequences, using the first two corners to predict the last two. Same method as before for generating noisy squares.
def generate_sequences(n=128, variable_len=False, seed=13):
basic_corners = np.array([[-1, -1], [-1, 1], [1, 1], [1, -1]])
np.random.seed(seed)
bases = np.random.randint(4, size=n)
if variable_len:
lengths = np.random.randint(3, size=n) + 2
else:
lengths = [4] * n
directions = np.random.randint(2, size=n)
points = [basic_corners[[(b + i) % 4 for i in range(4)]][slice(None, None, d*2-1)][:l] + np.random.randn(l, 2) * 0.1 for b, d, l in zip(bases, directions, lengths)]
return points, directions
1.4. Plain Encoder-Decoder¶
We use exactly the same encoder-decoder from Lab11’s sequence to sequence notebook.
class Encoder(nn.Module):
def __init__(self, n_features, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.n_features = n_features
self.hidden = None
self.basic_rnn = nn.GRU(self.n_features, self.hidden_dim, batch_first=True)
def forward(self, X):
rnn_out, self.hidden = self.basic_rnn(X)
return rnn_out # N, L, F
class Decoder(nn.Module):
def __init__(self, n_features, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.n_features = n_features
self.hidden = None
self.basic_rnn = nn.GRU(self.n_features, self.hidden_dim, batch_first=True)
self.regression = nn.Linear(self.hidden_dim, self.n_features)
def init_hidden(self, hidden_seq):
# We only need the final hidden state
hidden_final = hidden_seq[:, -1:] # N, 1, H
# But we need to make it sequence-first
self.hidden = hidden_final.permute(1, 0, 2) # 1, N, H
def forward(self, X):
# X is N, 1, F
batch_first_output, self.hidden = self.basic_rnn(X, self.hidden)
last_output = batch_first_output[:, -1:]
out = self.regression(last_output)
# N, 1, F
return out.view(-1, 1, self.n_features)
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, input_len, target_len, teacher_forcing_prob=0.5):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.input_len = input_len
self.target_len = target_len
self.teacher_forcing_prob = teacher_forcing_prob
self.outputs = None
def init_outputs(self, batch_size):
device = next(self.parameters()).device
# N, L (target), F
self.outputs = torch.zeros(batch_size,
self.target_len,
self.encoder.n_features).to(device)
def store_output(self, i, out):
# Stores the output
self.outputs[:, i:i+1, :] = out
def forward(self, X):
# splits the data in source and target sequences
# the target seq will be empty in testing mode
# N, L, F
source_seq = X[:, :self.input_len, :]
target_seq = X[:, self.input_len:, :]
self.init_outputs(X.shape[0])
# Encoder expected N, L, F
hidden_seq = self.encoder(source_seq)
# Output is N, L, H
self.decoder.init_hidden(hidden_seq)
# The last input of the encoder is also
# the first input of the decoder
dec_inputs = source_seq[:, -1:, :]
# Generates as many outputs as the target length
for i in range(self.target_len):
# Output of decoder is N, 1, F
out = self.decoder(dec_inputs)
self.store_output(i, out)
prob = self.teacher_forcing_prob
# In evaluation/test the target sequence is
# unknown, so we cannot use teacher forcing
if not self.training:
prob = 0
# If it is teacher forcing
if torch.rand(1) <= prob:
# Takes the actual element
dec_inputs = target_seq[:, i:i+1, :]
else:
# Otherwise uses the last predicted output
dec_inputs = out
return self.outputs
1.5. Attention Mechanism Explained¶
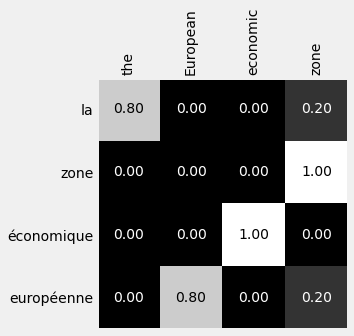
1.5.1. An illustration of Attention Scores¶
fig = figure9()
1.5.2. Context Vector¶
The context vector is the weighted average of encoder hidden states.
But how do we compute alphas - attention scores?
Let’s use our own sequence-to-sequence problem, and the “perfect” square as input to illustrate how the context vector is computed.
A sequence full_seq is splitted into source and target sequences.
full_seq = torch.tensor([[-1, -1], [-1, 1], [1, 1], [1, -1]]).float().view(1, 4, 2)
source_seq = full_seq[:, :2]
target_seq = full_seq[:, 2:]
1.5.3. “Values” and “Keys”¶
The source sequence is the input of the encoder. The hidden states the encoder outputs are going to be both “values” (V) and “keys” (K):
torch.manual_seed(21)
encoder = Encoder(n_features=2, hidden_dim=2)
hidden_seq = encoder(source_seq)
values = hidden_seq # N, L, H
values
tensor([[[ 0.0832, -0.0356],
[ 0.3105, -0.5263]]], grad_fn=<TransposeBackward1>)
keys = hidden_seq # N, L, H
keys
tensor([[[ 0.0832, -0.0356],
[ 0.3105, -0.5263]]], grad_fn=<TransposeBackward1>)
1.5.4. Query¶
The encoder-decoder dynamics stay exactly the same: despite that we are sending the entire sequence of hidden states to the decoder, we still use the encoder’s final hidden state as the decoder’s initial hidden state.
In this example of using the first two corners to predict the last two, we still use the last element of the source sequence as input to the first step of the decoder:
torch.manual_seed(21)
decoder = Decoder(n_features=2, hidden_dim=2)
decoder.init_hidden(hidden_seq)
inputs = source_seq[:, -1:]
out = decoder(inputs)
The first “query” (Q) is the decoder’s hidden state (remember, hidden states are always sequence-first, so we permute it to batch-first):
query = decoder.hidden.permute(1, 0, 2) # N, 1, H
query
tensor([[[ 0.3913, -0.6853]]], grad_fn=<PermuteBackward>)
1.5.5. Compute the Attention Score¶
Once we have the “keys” and a “query”, we can compute attention scores (alphas) using them. This is for illustration only, we will progressively develop the calc_alphas() to reflect the true processing in the digram.
Note
The alphas here do not make use of the values of keys and query, they are simply ones averaged by the sequence length.
def calc_alphas(ks, q):
N, L, H = ks.size()
alphas = torch.ones(N, 1, L).float() * 1/L
return alphas
alphas = calc_alphas(keys, query)
alphas
tensor([[[0.5000, 0.5000]]])
We had to make sure alphas had the right shape (N, 1, L) so that, when multiplied by the “values” with shape (N, L, H), it will result in a weighted sum of the alignment vectors with shape (N, 1, H). We can use batch matrix multiplication (torch.bmm) for that:
We can simply ignore the first dimension and PyTorch will go over all the elements in the mini-batch for us.
Warning
Why are we spending so much time on shapes and matrix multiplication?
Although it seems a fairly basic topic, getting the shapes and dimensions right is of utmost importance for the correct implementation of an algorithm or technique. Worst case is when using the wrong dimensions in an operation, PyTorch may not raise an explicit error, causing the almost undetectable Logical Error. This will ultimately damage the model’s ability to learn.
# N, 1, L x N, L, H -> 1, L x L, H -> 1, H
context_vector = torch.bmm(alphas, values)
context_vector
tensor([[[ 0.1968, -0.2809]]], grad_fn=<BmmBackward0>)
Once the context vector is ready, we can concatenate it to the “query” (the decoder’s hidden state) and use it as the input for the linear layer that actually generates the predicted coordinates:
concatenated = torch.cat([context_vector, query], axis=-1)
concatenated
tensor([[[ 0.1968, -0.2809, 0.3913, -0.6853]]], grad_fn=<CatBackward>)
In summary, the above can be summarised into the following steps of a typical attention mechanism:
encoder to get hidden states, which are used as
"values"as well as"keys"decoder to get the first hidden state, which is used as
"query"query and keys to work out attention scores,
alphas"values"weighted byalphasto getalignment vectorssumming up
alignment vectorsto get thecontext vectorconcatenate
context vectorwith the decoder hidden state (in this simplest case, the same asquery), for output predication.
1.6. Scoring Method¶
In the calc_alpha() function above, we used the simple \(\frac{1}{L}\) as weights, which produces an average of the hidden states. Below we show the use of dot product between Q and K as a scoring method.
1.6.1. Dot product¶
# N, 1, H x N, H, L -> N, 1, L
products = torch.bmm(query, keys.permute(0, 2, 1))
products
tensor([[[0.0569, 0.4821]]], grad_fn=<BmmBackward0>)
1.6.2. Attention Scores¶
alphas = F.softmax(products, dim=-1)
alphas
tensor([[[0.3953, 0.6047]]], grad_fn=<SoftmaxBackward>)
def calc_alphas(ks, q):
# N, 1, H x N, H, L -> N, 1, L
products = torch.bmm(q, ks.permute(0, 2, 1))
alphas = F.softmax(products, dim=-1)
return alphas
1.6.3. Visualizing the Context¶
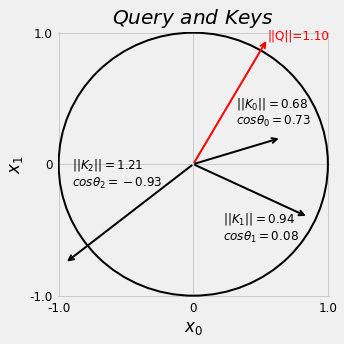
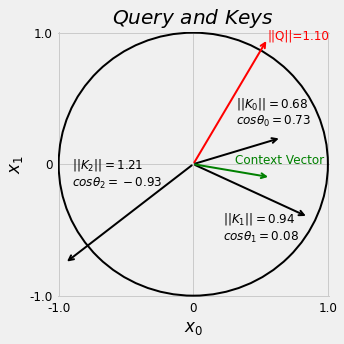
Here we use a single query (q) and three keys (k) to illustrate the idea of using dot products in measuring vector similarity. Visually, the red query vector (\(Q\)) is closer to \(K_0\).
q = torch.tensor([.55, .95]).view(1, 1, 2) # N, 1, H
k = torch.tensor([[.65, .2],
[.85, -.4],
[-.95, -.75]]).view(1, 3, 2) # N, L, H
fig = query_and_keys(q.squeeze(), k.view(3, 2))
# N, 1, H x N, H, L -> N, 1, L
prod = torch.bmm(q, k.permute(0, 2, 1))
prod
tensor([[[ 0.5475, 0.0875, -1.2350]]])
scores = F.softmax(prod, dim=-1)
scores
tensor([[[0.5557, 0.3508, 0.0935]]])
v = k
context = torch.bmm(scores, v)
context
tensor([[[ 0.5706, -0.0993]]])
fig = query_and_keys(q.squeeze(), k.view(3, 2), context)
1.6.4. Scaled Dot¶
The dot product score is sensitive to the length of the vectors, and we can normalise using the standard deviation, which is roughly the sequare root of the dimension of vector as verified using randomly generated normally distributed data.
1.6.4.1. Variance of a batch dot product is roughly the same as the dimension of the vector¶
n_dims = 10
dummy_qs = torch.randn(10000, 1, n_dims)
dummy_ks = torch.randn(10000, 1, n_dims).permute(0, 2, 1)
torch.bmm(dummy_qs, dummy_ks).squeeze().var()
tensor(9.7670)
dummy_product = torch.tensor([4.0, 1.0])
F.softmax(dummy_product, dim=-1), F.softmax(100*dummy_product, dim=-1)
(tensor([0.9526, 0.0474]), tensor([1., 0.]))
scaled_products = products / np.sqrt(2)
scaled_products
tensor([[[0.0403, 0.3409]]], grad_fn=<DivBackward0>)
alphas = F.softmax(scaled_products, dim=-1)
alphas
tensor([[[0.4254, 0.5746]]], grad_fn=<SoftmaxBackward>)
def calc_alphas(ks, q):
dims = q.size(-1)
# N, 1, H x N, H, L -> N, 1, L
products = torch.bmm(q, ks.permute(0, 2, 1))
scaled_products = products / np.sqrt(dims)
alphas = F.softmax(scaled_products, dim=-1)
return alphas
alphas = calc_alphas(keys, query)
# N, 1, L x N, L, H -> 1, L x L, H -> 1, H
context_vector = torch.bmm(alphas, values)
context_vector
tensor([[[ 0.2138, -0.3175]]], grad_fn=<BmmBackward0>)
1.7. Encoder Decoder with Attention Mechanism¶
1.7.1. Attention Class¶
class Attention(nn.Module):
def __init__(self, hidden_dim, input_dim=None, proj_values=False):
super().__init__()
self.d_k = hidden_dim
self.input_dim = hidden_dim if input_dim is None else input_dim
self.proj_values = proj_values
# Affine transformations for Q, K, and V
self.linear_query = nn.Linear(self.input_dim, hidden_dim)
self.linear_key = nn.Linear(self.input_dim, hidden_dim)
self.linear_value = nn.Linear(self.input_dim, hidden_dim)
self.alphas = None
def init_keys(self, keys):
self.keys = keys
self.proj_keys = self.linear_key(self.keys)
self.values = self.linear_value(self.keys) \
if self.proj_values else self.keys
def score_function(self, query):
proj_query = self.linear_query(query)
# scaled dot product
# N, 1, H x N, H, L -> N, 1, L
dot_products = torch.bmm(proj_query, self.proj_keys.permute(0, 2, 1))
scores = dot_products / np.sqrt(self.d_k)
return scores
def forward(self, query, mask=None):
# Query is batch-first N, 1, H
scores = self.score_function(query) # N, 1, L
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
alphas = F.softmax(scores, dim=-1) # N, 1, L
self.alphas = alphas.detach()
# N, 1, L x N, L, H -> N, 1, H
context = torch.bmm(alphas, self.values)
return context
1.7.2. Source Mask¶
source_seq = torch.tensor([[[-1., 1.], [0., 0.]]])
# pretend there's an encoder here...
keys = torch.tensor([[[-.38, .44], [.85, -.05]]])
query = torch.tensor([[[-1., 1.]]])
source_mask = (source_seq != 0).all(axis=2).unsqueeze(1)
source_mask # N, 1, L
tensor([[[ True, False]]])
torch.manual_seed(11)
attnh = Attention(2)
attnh.init_keys(keys)
context = attnh(query, mask=source_mask)
attnh.alphas
tensor([[[1., 0.]]])
1.7.3. Decoder with Attention¶
class DecoderAttn(nn.Module):
def __init__(self, n_features, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.n_features = n_features
self.hidden = None
self.basic_rnn = nn.GRU(self.n_features, self.hidden_dim, batch_first=True)
self.attn = Attention(self.hidden_dim)
self.regression = nn.Linear(2 * self.hidden_dim, self.n_features)
def init_hidden(self, hidden_seq):
# the output of the encoder is N, L, H
# and init_keys expects batch-first as well
self.attn.init_keys(hidden_seq)
hidden_final = hidden_seq[:, -1:]
self.hidden = hidden_final.permute(1, 0, 2) # L, N, H
def forward(self, X, mask=None):
# X is N, 1, F
batch_first_output, self.hidden = self.basic_rnn(X, self.hidden)
query = batch_first_output[:, -1:]
# Attention
context = self.attn(query, mask=mask)
concatenated = torch.cat([context, query], axis=-1)
out = self.regression(concatenated)
# N, 1, F
return out.view(-1, 1, self.n_features)
full_seq = torch.tensor([[-1, -1], [-1, 1], [1, 1], [1, -1]]).float().view(1, 4, 2)
source_seq = full_seq[:, :2]
target_seq = full_seq[:, 2:]
torch.manual_seed(21)
encoder = Encoder(n_features=2, hidden_dim=2)
decoder_attn = DecoderAttn(n_features=2, hidden_dim=2)
# Generates hidden states (keys and values)
hidden_seq = encoder(source_seq)
decoder_attn.init_hidden(hidden_seq)
# Target sequence generation
inputs = source_seq[:, -1:]
target_len = 2
for i in range(target_len):
out = decoder_attn(inputs)
print(f'Output: {out}')
inputs = out
Output: tensor([[[-0.3555, -0.1220]]], grad_fn=<ViewBackward>)
Output: tensor([[[-0.2641, -0.2521]]], grad_fn=<ViewBackward>)
1.7.4. Encoder + Decoder + Attention¶
We can safely use the orginal code for grouping the encoder and decoder (in this case, the decoder with attention), and create a valid model, but we would like to store the output to visualise attention scores.
encdec = EncoderDecoder(encoder, decoder_attn, input_len=2, target_len=2, teacher_forcing_prob=0.0)
encdec(full_seq)
tensor([[[-0.3555, -0.1220],
[-0.2641, -0.2521]]], grad_fn=<CopySlices>)
class EncoderDecoderAttn(EncoderDecoder):
def __init__(self, encoder, decoder, input_len, target_len, teacher_forcing_prob=0.5):
super().__init__(encoder, decoder, input_len, target_len, teacher_forcing_prob)
self.alphas = None
def init_outputs(self, batch_size):
device = next(self.parameters()).device
# N, L (target), F
self.outputs = torch.zeros(batch_size,
self.target_len,
self.encoder.n_features).to(device)
# N, L (target), L (source)
self.alphas = torch.zeros(batch_size,
self.target_len,
self.input_len).to(device)
def store_output(self, i, out):
# Stores the output
self.outputs[:, i:i+1, :] = out
self.alphas[:, i:i+1, :] = self.decoder.attn.alphas
1.7.5. Data Preparation¶
Training data of the square sequences generated.
points, directions = generate_sequences()
full_train = torch.as_tensor(points).float()
target_train = full_train[:, 2:]
test_points, test_directions = generate_sequences(seed=19)
full_test = torch.as_tensor(points).float()
source_test = full_test[:, :2]
target_test = full_test[:, 2:]
train_data = TensorDataset(full_train, target_train)
test_data = TensorDataset(source_test, target_test)
generator = torch.Generator()
train_loader = DataLoader(train_data, batch_size=16, shuffle=True, generator=generator)
test_loader = DataLoader(test_data, batch_size=16)
1.7.6. Model Configuration & Training¶
torch.manual_seed(23)
encoder = Encoder(n_features=2, hidden_dim=2)
decoder_attn = DecoderAttn(n_features=2, hidden_dim=2)
model = EncoderDecoderAttn(encoder, decoder_attn, input_len=2, target_len=2, teacher_forcing_prob=0.5)
loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
sbs_seq_attn = StepByStep(model, loss, optimizer)
sbs_seq_attn.set_loaders(train_loader, test_loader)
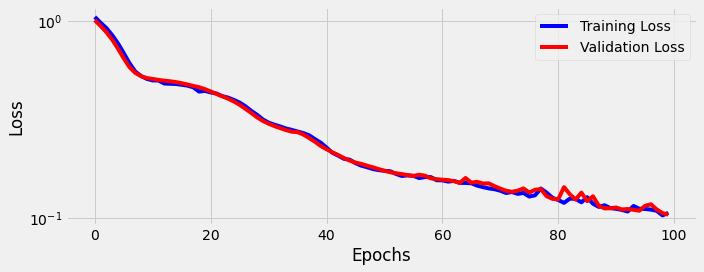
sbs_seq_attn.train(100)
fig = sbs_seq_attn.plot_losses()
1.7.7. Visualizing Predictions¶
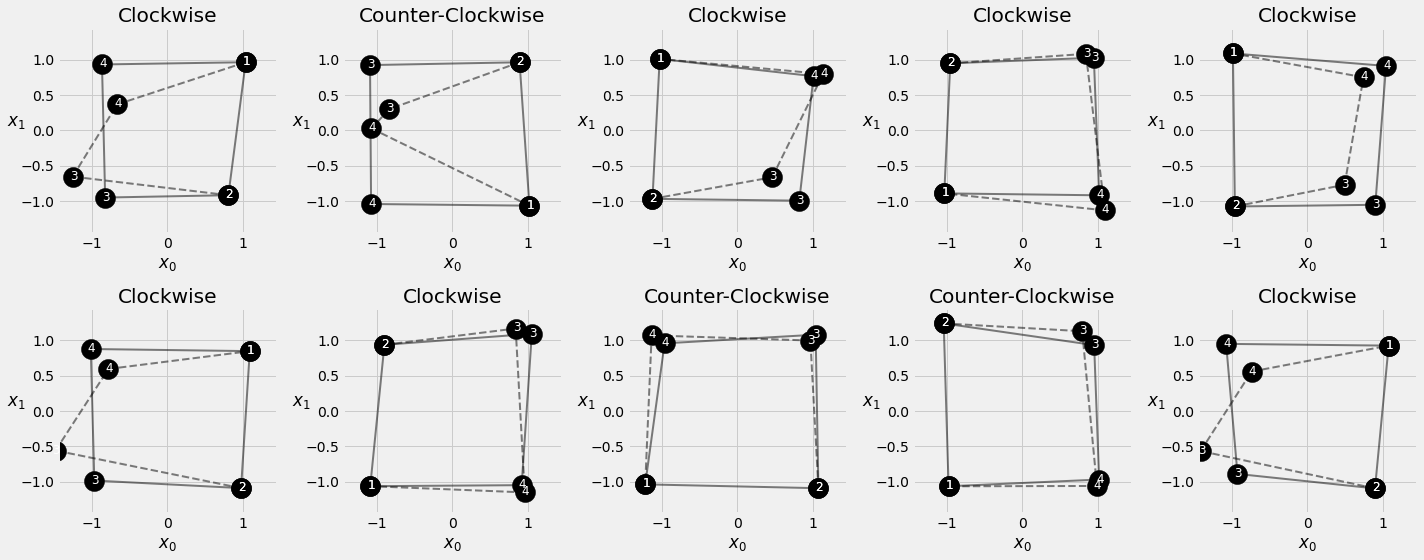
fig = sequence_pred(sbs_seq_attn, full_test, test_directions)
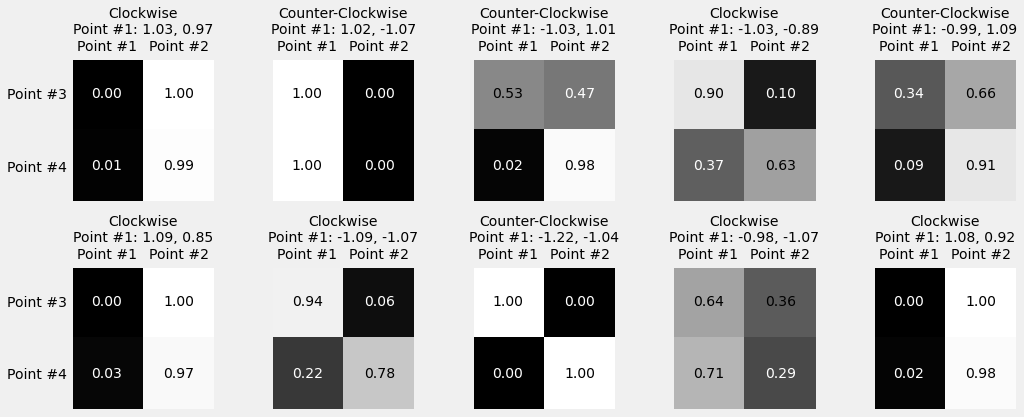
1.7.8. Visualizing Attention¶
inputs = full_train[:1, :2]
out = sbs_seq_attn.predict(inputs)
sbs_seq_attn.model.alphas
tensor([[[7.8848e-04, 9.9921e-01],
[1.0210e-02, 9.8979e-01]]], device='cuda:0')
inputs = full_train[:10, :2]
source_labels = ['Point #1', 'Point #2']
target_labels = ['Point #3', 'Point #4']
point_labels = [f'{"Counter-" if not directions[i] else ""}Clockwise\nPoint #1: {inp[0, 0]:.2f}, {inp[0, 1]:.2f}' for i, inp in enumerate(inputs)]
fig = plot_attention(model, inputs, point_labels, source_labels, target_labels)